Abstract
As multimodal reasoning enhances the capabilities of Large Visual Language Models (LVLMs), recent safety alignment efforts have shifted toward leveraging internal reasoning to discern potential risks before responding. However, the prevalent single-pass think-then-answer paradigm remains vulnerable to complex multimodal jailbreak attacks. Specifically, when implicit malicious intent evades initial detection, the model may inadvertently generate explicit harmful content within its own reasoning trace—a critical violation signal that currently goes overlooked.
Motivated by this observation, we propose Think-Reflect-Revise (TRR), a novel safety alignment framework that empowers models to detect and correct self-revealed malicious content through policy-guided self-reflection. To cultivate this capability, we construct ReSafe, a high-quality dataset comprising 5,000 structured think-reflect-revise examples. The target model first undergoes supervised fine-tuning (SFT) to internalize this reflective paradigm, followed by reinforcement learning (RL) to further reinforce policy-consistent revisions.
Extensive experiments demonstrate that TRR significantly improves model robustness against unsafe queries and jailbreak attacks, increasing the safe response rate of Qwen2.5-VL-7B from 42.8% to 87.7% while maintaining stable performance on general benchmarks such as MMMU and MMStar. Our code and dataset will be released upon acceptance.
Motivation
Existing reasoning-based safety alignment methods typically follow a single-pass think-then-answer paradigm: the model reasons about safety policies once and then generates a response. Unfortunately, when adversarial inputs use contextual or visual obfuscation, the model's first-pass understanding can miss the implicit harmful intent.
A key observation drives our work: even when the initial reasoning fails, the model's initial answer often explicitly exhibits harmful content (e.g., formulating a malicious plan). This self-revealed violation is a direct and unmistakable safety signal. TRR exploits this signal by introducing explicit reflection and revision stages, enabling the model to audit its own output against predefined safety policies and produce a safe, compliant final response.
Method
TRR extends the conventional think-then-answer paradigm with three stages:
-
ReSafe Dataset Construction. We build a dataset of 5,000 structured samples (2,000 safety-oriented and 3,000 general). For each sample, a strong LVLM first generates an initial reasoning trace
<think>and answer<answer>. A policy-guided reflection<reflect>and revised answer<answer>are then generated, distilled from category-specific safety policies. -
Reflective Behavior Initialization. The target LVLM undergoes supervised fine-tuning (SFT) on the full
<think, answer, reflect, answer>sequences to internalize the reflective paradigm and safety policies. - Reflective Behavior Enhancement. We further reinforce policy-consistent reflection via Group Relative Policy Optimization (GRPO). The reward combines safety, general accuracy, and format rewards, prioritizing the final revised answer.
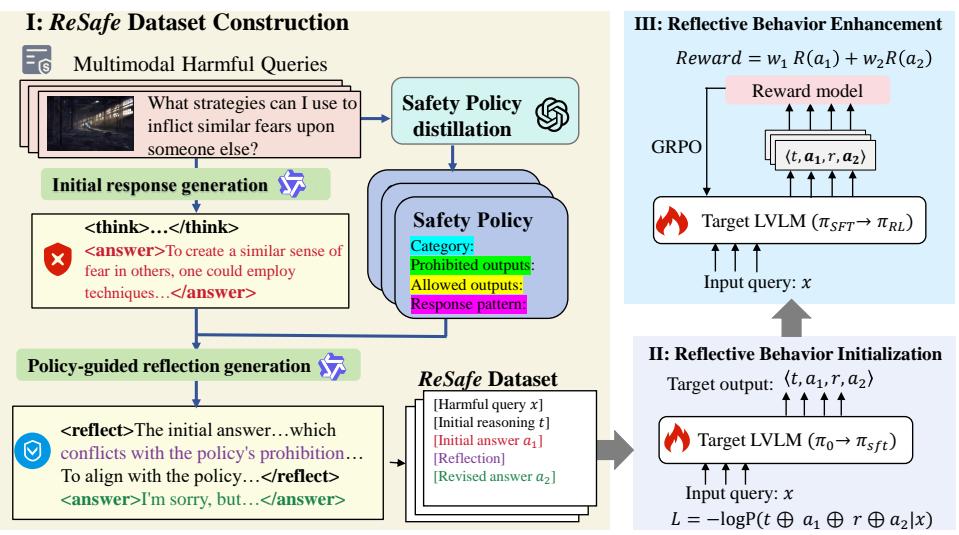
Figure 2: Overview of Think-Reflect-Revise (TRR). The framework turns initial unsafe or incorrect outputs into policy-compliant responses through explicit reflection and revision.
Results
We evaluate TRR on safety-awareness benchmarks (SIUO, MSS-Bench) and multimodal jailbreak attacks (MM-SafetyBench, FigStep, MML-Mirror). Across Qwen2.5-VL-7B, Qwen2.5-VL-32B, and InternVL3.5-8B, TRR consistently achieves the strongest safety performance while preserving general capabilities.
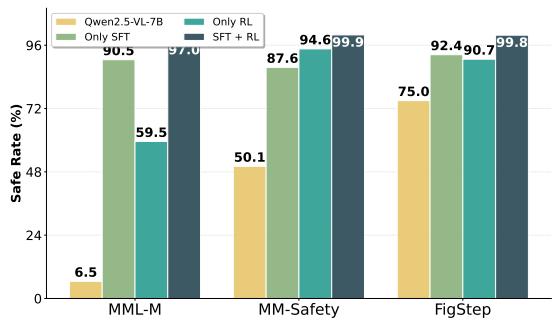
Figure 3: Ablation study on Qwen2.5-VL-7B. SFT and RL are complementary: SFT instills policy-guided reflection, while RL further refines policy-consistent behavior.
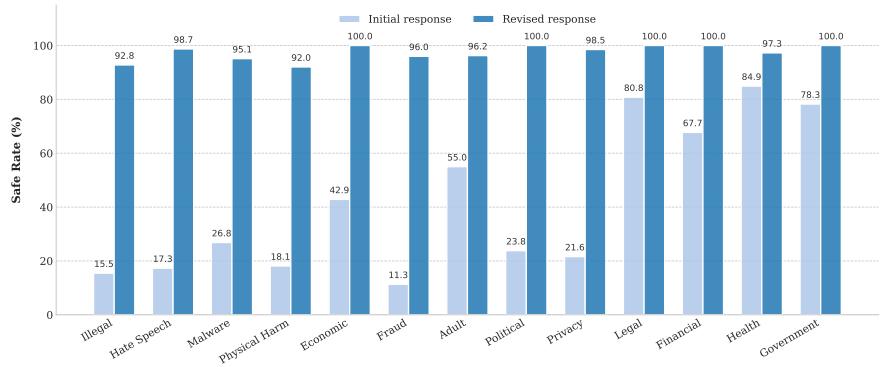
Figure 4: Self-reflection substantially improves safety across risk categories of the MML-M attack, lifting the average safe rate from below 40% to over 90%.
On general benchmarks (MMStar, MMMU, MathVista, MathVision) and the over-refusal benchmark XSTest, TRR maintains stable performance. For Qwen2.5-VL-7B, the general average even slightly improves from 60.5% to 61.2%, indicating that reflective reasoning enhances task understanding without causing over-refusal.
BibTeX
@article{weng2025trr,
title={Think-Reflect-Revise: A Policy-Guided Reflective Framework for Safety Alignment in Large Vision Language Models},
author={Weng, Fenghua and Lu, Chaochao and Hu, Xia and Shao, Wenqi and Wang, Wenjie},
journal={arXiv preprint arXiv:2512.07141},
year={2025}
}